You have a good point, if we’re treating the infinite TT as a physical object where falling balls have to go through the levers, then yes, numbers cannot be infinite in extent because otherwise, there would be an infinite expanse between two points in space, which is not possible here. However, I think there is a useful shortcut: if there are no pieces below a falling ball, it instantly reaches the end.
Now we can actually treat numbers as infinite and we can offset registers diagonally to one side so it’s possible to access an infinite number of registers. I think in this way, a counter machine can be constructed.
Edit:@paul, attempting to build a working processor would be very painful and frustrating if TT is not TC. When I and the others did Tetris in GoL, we already knew that GoL was TC. It’s better to prove TC then build a processor.
I’m so excited about this discussion! I wrote my thesis about proving Turing Tumble last year. The summary of my thesis is available on this page (Please click second “here” on the page, my paper starts at the page proc-25). I’m not sure whether this is a formal proof, but I think this is one way to prove completeness of Turing Tumble.
In my proof, I considered Reversible Logic Elements instead of logic gates (e.g. NAND), and I think RLE is suitable for Turing Tumble. An RLE is an element with input lines and output lines and it communicates with other elements via exchanging tokens on input/output lines. So Turing Tumble is similar to RLE based circuits, and it has proven that RLEs can construct Turing Machine (ref.). I think the most difficult part is the moving direction of balls. Because balls can move only downwards, it is difficult to send information to the above elements. I believe the reason why gear bits are needed is gear bits are usable for this purpose.
This blog post is also interesting. This is written about completeness of Digi-Comp II that a toy computer similar to Turing Tumble. In the post, it has been concluded that Digi-Comp II is not universal. That may be helpful for us.
The focus on infinite I/O is not merely a distraction I think.
On a PC we implement a Turing Machine application. Then if we use hard drives as the “tape” in our TM app we can swap drives in/out as needed to provide more tape. The limit is that there aren’t enough atoms in the universe to provide an infinite number of hard drives. If we assume an infinite supply of hard drives is available, a regular computer is very much Turing Complete. The TM/PC has finite memory because the universe is finite, not because of an inherent property of the machine.
I’m not so sure about TT, though. As there is no external tape to read/write, the TT is bounded by its initial configuration. Setting aside problems of having a TT board of infinite size, you’d never finish putting the pieces on the board.
But seriously, if you create an area of storage bits on the TT board it must grow horizontally or vertically… As the storage area grows horizontally the ball drop moves up to allow for the balls to go left and right far enough to reach the left-most and right-most bits. This means the ball drop is infinitely far away from the entire storage bits area… game over. If the storage area grows vertically, you might be able to get around the physical constraint of the ball never reaching the bottom by making the assumption that any ball that goes into free space immediately reaches the bottom. But to me that feels like a cheat.
What I’d like to see for Turing Tumble is an expansion pack where we can actually use a gear to move a portion of the board itself up or down (or left/right). Then you can define your TM in TT around a fixed head location and move sections of the board containing only bits (aka the “tape”) up and down. Having only a portion of the board that needs to be infinite gets around the problem of the balls needing to fall all the way to the bottom of an infinite space.
The other way to get around the infinity issue with TT is to allow for a human operator to be involved. One can certainly build a finite TT board that has a set of I/O registers and interrupts that would allow the operator to consult an infinite tape, set the bits appropriately, restart the machine, on the next interrupt, the operator would write the value of the registers to the tape, and move the tape left/right accordingly. Restart the machine. Ad infinitum. Of course, the operator may grow old and die before the machine stops… but I don’t think this should be considered a limitation.
[disclaimer: I’m not a computer scientist by any stretch of the imagination, I’m just having a fantastic time thinking about this stuff from a layperson’s perspective]
There are two limitations to showing any type of “completeness”…
Turing completeness, and any notion of (“linear bounded automata completeness”) will only be possible for models of computation which can recognize infinite languages (not infinite length strings, but strings of any arbitrary finite length). (By “language” for the non-CS people, I mean a subset of bitstrings out of all possible bitstrings. For example, consider the set of bitstrings that are the binary representations of a prime number. This is an infinite language. Or bitstrings with an odd number of 1s. Also an infinite language (though each string we consider is finite). The latter can of course be recognized by a finite state machine with two states.
Even ignoring 1., a model of computation that is in essence a finite device with finite number of parts each with a finite number of states, like Turing Tumble (TT), and without any external extensible memory, cannot do anything more than what a finite state machine can do. As Michael points out, computers as we have today are in essence finite state machines, unless we incorporate the possibility that they have additional memory, as much as needed, to read and write to.
It doesn’t make sense to ask the question “Is TT Turing-complete” until we define what a TT computation is formally. And, any way I see of formulating what a TT computation is, seems to fail at least on point 2, and perhaps on point 1. (Even if we allow an infinite board, and use of the board as memory - it is not at all clear how the machine can decide to add more bits to its memory. Who puts these pieces on the board? Or, does it start off with an infinite array of bits? There are other issues or reachability of gates that Michael alluded to. I can think of some ways to extend TT to possibly accommodate a “tape”, but then it is not TT anymore.)
In light of the above, I think the right thing to be asking instead of about completeness is the question of universality - whether any arbitrary Boolean function of n inputs can be computed with TT. It is easier to think about this than about simulating a microprocessor. And if the answer is “yes”, then TT can compute anything a computer can (if we take the theoretically justified but practically flawed view that a computer can only compute boolean functions). I’d suggest we start by trying to show that we can evaluate a function whose disjunctive normal form has, say, two terms. For example, if the inputs are x1, x2, x3, x4, x5, then output “1” (intercept a blue ball, or, set an output bit to the right) if the bits are flipped to either satisfy (x1 and x2 set to 1 and x4 set to 0), OR (x1 and x3 set to 0, and x5 set to 1). Otherwise, intercept a red ball, (or set an output bit to the left). Note, just because we can build AND, OR, and NOT gates, doesn’t make this trivial; it is not clear to me at least how you compose these on the TT board, given that a computation happens with one “electron” moving through the “circuit” at a time.
I consider Turing completeness to be a property of the theoretical model under consideration, unhindered by practical constraints. You can simplify Turing Tumble to a model where, aside from the ramps, crossovers, bits, gears, and gear bits, there is one ball drop and either balls in free space drop immediately to the “bottom” or one may place an infinite number of flippers. The important thing in that last bit is that the next ball is released when the previous one is “done”.
As long as it doesn’t take an infinite amount of time or space to do any finite operation or computation, then that’s fine, even if the constructs involved are infinite in extent. As an example, a register of infinitely many bits can still be used to add 1 indefinitely - all balls going through will exit on the right side eventually, which can then trigger the next ball.
@OUDON: I’ve read a little bit of your paper so far, and I’m having difficulty understanding it due to my lack of knowledge and experience in that particular area. Do you think you would be able to write up an explanation suitable for a layman?
That paper was indeed fairly interesting. It’s very much worth noting, however, that the author explicitly excluded switches, which are equivalent to TT’s bits. Also worth noting that Digi-Comp II did not have gear bits, so far as I could tell, so that’s another way that TT has more functionality.
Or it can grow diagonally. I do not see any reason why one cannot have an infinite progression of columns to one side and use an insane amount of ramps and crossovers to direct the output of bits to the appropriate columns. I don’t yet have a solution though, methinks I’ll post it as a theoretical challenge.
I was considering using bits as the switching mechanism to direct the ball to a particular problem, but the problem is that either 1) some column will be hit more than others, which may be okay depending on the design of the rest, or 2) balls have to pass through an infinite number of bits, which is forbidden. Gear bits may provide a solution however, given the ability to “reset” specific gear bits.
As long as any given column can be reached in finite time, there is no problem to having an infinite number of columns.
CSS + HTML is Turing complete…if you consider a human operator clicking particular boxes as part of the system. Also, the way you’ve described it, the operator is doing the vast majority of the work in simulating a Turing machine, so I don’t think that really counts either.
I’m not a computer scientist either, just someone that knows a little about this stuff.
Unfortunately, I never got the hang of working with language-based models of computation. It’s harder for me to think about that than to explore mechanical constructs needed for specific operations. Not to say that you shouldn’t; just saying that I’ll have a hard time following without more explanation and elaboration.
Hence, we shouldn’t think about physical devices. The real Turing Tumble must be the inspiration for a theoretical model.
An infinite board must have an infinite array of bits placed by some rule or algorithm.
For me personally, this seems much easier and less interesting. You have a point in that it’s non-trivial given that we only have one ball going through the system at a time, but I have a gut feeling that this is not a huge obstacle.
As an aside, bits must be used for input and/or output in the general case of any computation. Consider the problem of calculating 3 * 5 using only balls. I’m pretty sure it’s effectively impossible (or at least, very very difficult without extra external information or more colors etc) to distinguish input/output balls from the ones required to drive the machine.
A potential candidate for proving TC of TT is to simulate Rule 110. The main difficulty there is covering all of the columns needed for any given computation without iterating through all of them, unless we handwave it and say that we assume unneeded columns are not computed.
That’s cool - but I don’t understand how this can be used to simulate reading/writing from a tape. Even if we assume the layout begins with an infinite diagonal line of these devices, the program itself - the (finite) parts layout that implements the finite control - must be placed somewhere. Once it is placed, how does it have direct read/write/access to the memory elements that are far away? Perhaps I am not seeing something, but I think this problem applies to any layout where we don’t allow relative motion between the finite control and the memory units.
I think the model that has the most promise is the one @Michael proposed: we have part of the board that can move via gears. Let me explore this a bit further - here is a concrete simple model which I believe is in the spirit of TT, and about which we can inquire whether any TM can be simulated:
There is a horizontal strip of bits that extends indefinitely to the right and left… This strip is at the top of the board., and just below a ball drop.
The finite initial input to the TM is encoded on the bits, starting with the bit below the blue drop, and extending to the right. Bits past the encoding in each direction are all initially set to 0. [there is a question as to how the machine determines where the encoding ends, but there are well-known coding tricks so that this can be dealt with].
The “program” or finite control is placed somewhere below - a finite number of traditional pieces, with the exception of two new pieces: a gear that when a ball rolls over it, makes the read/write strip move one bit to the left, and one which makes it move one bit to the right. At the bottom, below the finite control pieces, the user may place a lever to trigger more balls. (There is no need to have both red and blue balls - since the balls are being used only to drive the computation.)
There are a number of possible generalizations that we might allow… for example. the horizontal sliding bit memory strip might be placed below some of the program pieces instead of at the top - which would allow the machine to potentially “read” as far to the left and right as the finite number of program pieces extend. This would be comparable to a TM that could read a finite number of adjacent cells at once. This doesn’t extend the power of a TM, but might make it easier to program the TT to simulate one.
Given this model, perhaps a next question is whether somebody can think of a computation that this device can perform that makes use of the memory and could not have been performed with the TT as it comes in the box.
Here is one of the simplest things I can think of: unary addition. The input has m consecutive 1s, followed by a 0, followed by n consecutive 1s. When the computation is done, the tape must show m+n consecutive 1s. Example input: 11110111. Ouput: 1111111. A trivial (two-state) TM solution is to replace the first 1 with a 0, then scan right and replace the first 0 with a 1. Challenge: Is there one of these TT-with-sliding-memory strip that can do this computation?
One can have the program counter/tape head represented by a particular column of gear bits that are linked with the tape’s gear bits via long chains of gears. A concern I have here is that there might be issues with crossing chains of components, and potentially also issues with the bi-directional nature of gears (turn any of the gears or gear bits and they all turn).
There are additional engineering challenges with the route I’ve been exploring, such as copying the value of one register to another. I’m not sure that directly simulating a TM is the way to go, but I’m learning as I go.
I just realized that if I want to continue down the route of directly simulating a TM, then I need to solve a very similar problem: given a string of 0s with one 1, move that 1 to the left or to the right on demand. I think it’s doable with gear bits though I don’t yet have a solution.
I was assuming that besides the memory, the program layout itself is finite, otherwise I feel we are cheating by having an “algorithm” which is not finite. It sounds like you are proposing that the simulator itself is infinite. Even if we allow all of the (infinity of) pieces needed to connect the memory, it seems you still need an infinite number of parts besides that. Am I missing something?
I guess I don’t fully understand your model. What and where are all the pieces that are on the board initially, before I lay down a finite number pieces that represent the program?
The center of the tape is located somewhere below the ball drop and the tape extends infinitely far to either side, diagonally downward. (Alternatively, the tape extends infinitely far to one side with the “negative” branch being located underneath the “positive” branch, offset horizontally to avoid interference.)
Somewhere else, the program counter is located to store the location of the tape head. There’s plenty of room below the tape and crossovers can be liberally used to avoid interference.
In yet another location, the program is stored and interacted with via yet-to-be-discovered mechanisms.
Anywhere an unbounded integer is needed, there exists an infinite column of bits extending downward. Any operation involving finite integers here will complete in finite time since the extra bits are effectively just leading zeroes and we deal with those on a daily basis just fine. (Either avoid negative integers or use the first bit to indicate sign.)
There’s really not much detail to speak of yet. I only just worked out the tape mechanism yesterday after all.
Edit: I think the following mechanisms are required:
An infinite tape
Store current head position
Store current state
Read bit at current head position
Check program table for current bit + current state
Write bit at current head position
Set new state
Move the head 1 step to the left or right
I get the sense that it will probably take multiple balls and lots of gears to do one step.
Thank you for reading my paper! Actually, I think that the paper is too short to understand it. I want to try to write up the explanation. But it will probably take a long time to that, and please give me some time.
And I’m interested in your ideas that simulating Counter Machines or Rule 110 on TT. I can’t wait to read your proof.
OK - I think I understand where you’re heading now. Seems to me that with either approach (sliding strip of bits to represent the tape, or infinite diagonal or column of bits to represent memory and unbounded numbers), a significant challenge will be to implement an arbitrary finite-state control. With your intended design, I think there may be an additional challenge also in being able to increment, or decrement, a number as desired. At least the way I’ve been solving problems in the puzzle book, each design requires either a fixed layout that adds one to a binary number, or a different layout that subtracts one, and these use fixed ramps that point in opposite directions. A mini-puzzle might be to create a mechanism that adds one to a number on receiving a ball from one direction (say, a blue ball), and subtracts one on receiving one from a different direction (say, a red ball). Actually, if you couple two such counters with a finite control, you’ve got a two-counter machine, which surprisingly is powerful enough to simulate a TM, so we’re done.
I can’t say I follow all the theory here about Turing Completeness, but I believe I have designed a “metapixel” that can implement any 1D elementary cellular automaton. This includes Rule 110, obviously, so if it works I guess it would constitute a practical proof? Well in any case it’s the best I can do because a formal proof is out of my league at this point.
I’m not sure how well it handles the infinite extent requirements, but it lays the cells out vertically, so the width is smallish and fixed. The height varies with the number of cells being simulated, and can in theory be extended indefinitely. It requires only one ball per generation, and side/color is irrelevant. There will be some issues with edge conditions at the top and bottom, which could be crudely solved by padding. There also may be a proper solution to make it behave like a ring, but I haven’t fully considered that yet. It could involve either some fanciness with ball side/color or some VERY long strings of gear-bits.
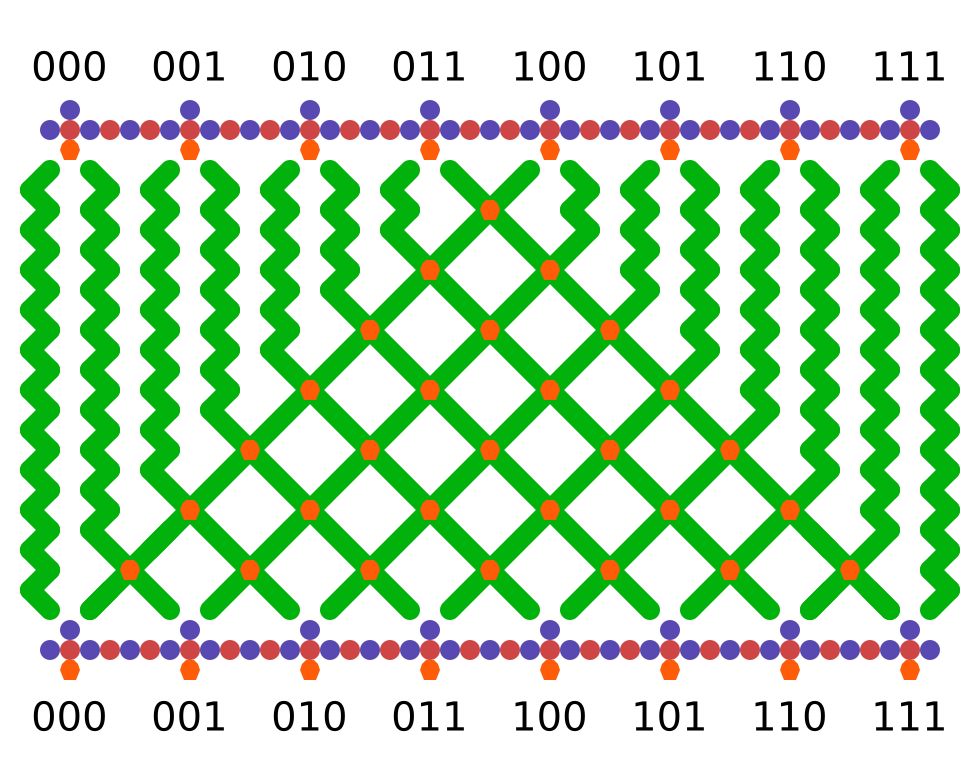
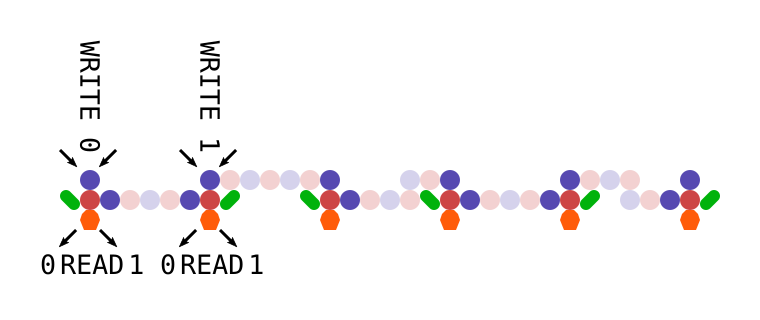
Okay, on to the solution. The mechanism effectively stores a 3-bit register, using horizontal ball position to encode its contents. The core operation that can be performed with this register is to shift one bit onto the end of it, moving the rest one position left, such that ABC become BCD. This shift operation is accomplished by the following unit (there are a lot of parts so I’m using a schematic representation of the board):
So regardless of which position the ball arrives in, the value from the set of gear-bits at the top is non-destructively read and the ball is routed such that its value is shifted onto the end of the register. In this way, the running value of three cells can be stored. To implement the CA rule, we route the ball through units that perform a destructive read:
There are two types of units, one which writes a 0 and one which writes a 1, but either will use the prior value of the bits to route the ball in the same way as the units above. As you can see, they can be arranged on the same spacing, and any combination of units can be geared together without interfering with their function. By placing eight writers into the appropriate positions, we can implement any elementary CA rule.
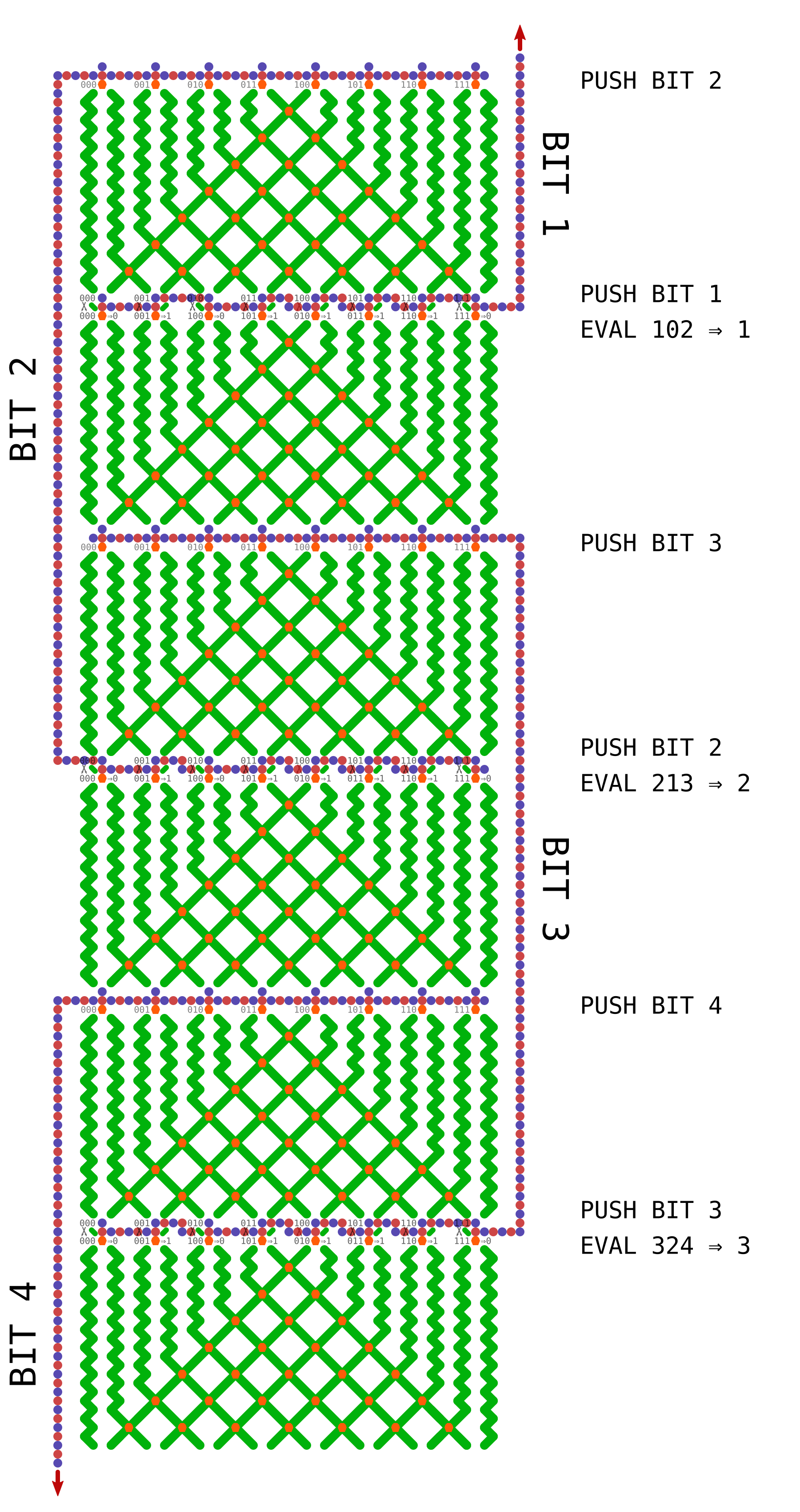
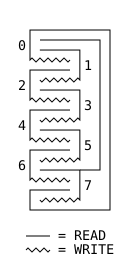
The remaining step is to arrange these units in a continuous chain and propagate some information upward as the ball drops (and we can’t cross gear chains (yet)). This is done using a topology of interlocking C shapes. Each C is a long chain of gear-bits representing one cell in the automaton, with a read stripe at the top and a write stripe at the bottom. Half the cells push up information on the left and half on the right:
That’s a big image, but metapixels do seem to spread out… I just realized I probably could remove some space between parts and make this about half the size, but I drafted it with extra room just in case. Anyhow, because of the order in which the bits are pushed onto the stack, the rule isn’t laid out in the usual way. Each time it’s evaluated, the order of the cells is BAC => B, CBD => C, DCE => D, etc, so the current cell and its “left-hand” neighbor are always switched. It’s pretty trivial to map the rule, and I figured it was easier to do that than something like using multiple types of routing panels to get the order into the canonical form each time.
So, I’m fairly sure this would work but would appreciate more eyes on it. Also, is there a simulator that can handle arbitrarily large boards? That might come in handy if we’re going to continue speculating about theoretical problems.
EDIT
I think making it into a ring works out okay, although it involves very long chains. But hey, if we’re imagining infinite boards we can imagine constant friction too. Here’s one topology that I think would work, forming a ring of eight cells.
This game is keeping me up at night Paul! It said “addictive” right there on the box, but did I listen?
Regardless of whether this is right or wrong, or works or not, this seems ingenious. There is a lot here to digest, and I’m trying to understand it, and my head hurts I’m a bit confused and fuzzy about the high-level idea though. Here are some basic questions which may help me: Let’s suppose that you are only simulating the evolution of a fixed-length string (I guess we assume for the purposes of rule 110 that non-existent neighbors at the ends are treated as 0s).
Before any ball drops, how is the state of the initial string represented? Is each “C” chain of gear bits flipped to 0 or 1 to indicate the value of the corresponding bit in the input?
When a ball drops in, what column does it drop into, and how is that achieved, both for the first, and for subsequent balls? If the initial string began 11011, then wouldn’t the ball need to feed into megapixel 1 in the 011 column (pretending that the nonexistent bit to the left were a 0)? How did it get there?
If the initial string were 11011, then upon arriving at megapixel 3, Rule 110 would indicate that the third bit should now change to a value of 1. How is that change represented? Wouldn’t the ball need to exit in column 111, which is not reachable from 101? Or would the ball be routed to 011, because that is the current generation’s values surrounding the fourth bit? And then the C chain representing the third bit would flip to a 1 to indicate the next generation value?
If the C chain of the third bit flips to a 1 per rule 110 after the ball passes through it, then isn’t the new value of 1 propagated via the C into bit 4’s megapixel? Doesn’t this affect the routing and update of bit 4, so that its update is based on the new value bit 3, and not the old value?
After a generation is updated, and a new ball is triggered, doesn’t the new ball have to find its way to the correct column indicating the value of the first two bits (edge condition). I.e., if the new generation began 11, then assuming we’re treating the nonexistent left neighbor of the first bit as a 0, wouldn’t the ball need to find its way to column 011?
As you can see from the above questions, I’m pretty confused. Any light you can shed on this would help me. This is very intriguing indeed.
Great questions! Yeah, I was writing it all up near midnight, so probably was not as clear as I’d have liked to be. The number of bits in the string would be fixed, however the schematic at the end of my post suggests it’s possible to treat the two ends as neighbors, forming a topological loop, which takes care of edge effects. It would also be possible to treat the end neighbors as zeros, by always routing the ball at the top into the 000 column, and by having a fixed routing that pushes 0 onto the stack before the last write stripe.
Yes that’s exactly right, and the output would be read out in the same way.
It actually doesn’t matter what column the ball drops into, assuming we use the loop topology like the schematic at the bottom, and assuming the bit-shifting sub-unit works as intended. If you look at the black-and-white schematic at the end, the ball falls through three “read stripes” before it hits the first write stripe, so three bits have been pushed onto a three bit register and all information about the initial column has been lost. An essential part of the design is to throw away one bit of information each time the ball goes through a stripe.
I think the confusing thing here is that when we’re about to apply the rule to a bit, call it C, that bit was actually pushed onto the stack two levels above, so the order of the bits we’re evaluating would be CBD instead of the usual BCD. You might be able to intuit this just from the shape of the C units, because the top of each C is always three steps above the bottom, and the center of the C includes one bit from above and one from below. Regardless of the order the bits are in, we can encode any rule as long as that order is consistent. Not really sure if that clears anything up, but just imagine pushing a bit into the register every time the ball passes through a stripe, whether it’s reading or writing.
No, the “destructive write” sub-unit writes a 1 or a zero, but always reads the bit’s prior value. So just as bit 3 is about to be shifted off the left end of the stack, its current value is shifted back onto the right end so it can act as a neighbor for bit 4. After that, the ball can never pass through bit 3 again until the next generation, so the new value won’t affect the result. Maybe a good way to explain the evaluation order is to write out the string of bits being pushed onto the register, and then pull out all the groupings that are evaluated as neighborhoods. So following the black-and-white schematic above, the bit stream going into the register looks like this:
As you can see, each cell has its neighborhood in the register when the rule is evaluated, only the positions of the current cell and its left-hand neighbor are swapped.
If you look at the bitstream breakdown above, you can see that three bits have been pushed by the time the first bit needs to be evaluated, so the initial position of the ball should have been lost and it doesn’t matter where we drop it in. However, as a side note I was thinking that a general-purpose computer would be much easier to implement if we could have any number of ball-drop/lever combos (i.e. considering that unit like any other part). If we had that, we could preserve the ball’s position between runs and use it to pass potentially quite a lot of information from the bottom of the board to the top without worrying about crossing gear trains. I’d expand on that idea but it’s off-topic for the moment. Although dang, I just started to wonder what really stops us from warping the board into a giant cylinder (in our imaginations of course), and rotating it as the ball drops such that the ball is always seeing the proper slope? It hardly seems like the board being planar is an essential requirement of the TT “platform”. Heck if you really want to bend your brain, imagine the TT as a mobius strip…
Anyway I hope that helps a little? I’m strongly considering investing some time in writing a simulator that can handle boards of arbitrary size, because part of the difficulty here is that we have to execute these kind of designs in our heads and it does start to bend the brain. Several times in writing the above post, I was sure I’d screwed something up, and I definitely am not ruling that out until I can see a CA rule running correctly on simulated hardware.
EDIT
Just noticed that I replied to the thread instead of to you @lennypitt, so tagging you now.
Also, I just remembered a question asked elsewhere on the forum about how to translate the insights gained from the TT into insights about the computers we’re familiar with. I think the missing link could be filled by software. Working with the board builds our intuition about the components, then we can carry that into a software simulation and continue to build larger and larger machines there, just as @elendiastarman and co did with WireWorld and GoL. This process could truly bridge the gap to “real” computers. So @paul, are there any plans for a software extension? I have the ambition and capability to do something really pretty and powerful, but we’ll have to see if I can actually commit the time. Regardless, I’d be into joining in on a group effort if such is being organized, or laying the foundation layer if not.
I haven’t had a chance to digest this yet. But, I was thinking about how to extend what I did in another post (computing any Boolean function of N bits to 1 bit) so that it could compute any function from N bits to N bits. It is easily extended, and, using your “C” idea, the output can be piped back up to the input bits, creating a feedback loop. You need N nested Cs. A decision tree is used at the top to divide into 2^N paths (in your language, we’re “pushing” N bits). Then, we just write the N bits. So, I think this is a simpler way of doing what you’re trying to do, since we can encode any funciton (including those corresponding to cellular automata).
I tried to create a demo of 3 bits to 3 bits with the feedback loop, and ran tight on space because I couldn’t yet get the tree to spread out enough. But, I do have it working for six of the eight possible inputs -for some inputs, I’m just intercepting the ball. (Note: the innermost feedback “C” isn’t a “C” - space ran tight so I had to modify it a bit so it is an upside down U.)
I’m not sure what function is encoded - I made it somewhat arbitrary, and in some cases, I ran out of space and things should be more spread out, so chose a value to output that used less space. and didn’t interfere with another path. In other places, I just terminated the path with an interceptor. But, if you set the input so that the first bit is 1, then it will work just fine. On the other side of the tree, there is only one input that is not intercepted. I might be able to redraw this to make it complete by shifting everything a little bit, but I didn’t have the energy and have out of town guests arriving, so that will be another day.

 Then you can define your TM in TT around a fixed head location and move sections of the board containing only bits (aka the “tape”) up and down. Having only a portion of the board that needs to be infinite gets around the problem of the balls needing to fall all the way to the bottom of an infinite space.
Then you can define your TM in TT around a fixed head location and move sections of the board containing only bits (aka the “tape”) up and down. Having only a portion of the board that needs to be infinite gets around the problem of the balls needing to fall all the way to the bottom of an infinite space.